JUNE 24 2025
From raw data to actionable context: building smarter AI agents
Building AI agents that get smarter over time by using knowledge graphs to transform conversational data into persistent context that improves decision-making.
The promise of AI agents has captured the imagination of enterprises everywhere, but as Kevin from Hypermode pointed out in a recent ODSC webinar:
"Most people are building agents wrong."
The fundamental challenge isn't the technology - it's the approach. Let's explore how to design smart agent memory systems that transform raw data into actionable context.
The communication gap in agent development
The typical agent development process often follows a flawed pattern. A well-meaning executive mandates AI adoption, leading to a game of telephone between subject matter experts and AI developers. The nuance of domain expertise gets lost in translation, resulting in agents that miss the mark.
The solution? Invert the workflow. Instead of having AI engineers interpret business requirements, empower domain experts to directly train and iterate with agents. This "hire, iterate, integrate" approach allows those who understand the job best to shape the agent's behavior through natural interaction.
Understanding agent context: the augmented LLM
At its core, an effective agent extends beyond simple prompt-response patterns and is able to both understand and act on its environment. As the "Building Effective Agents" blog post from Anthropic describes, we need an augmented LLM with three key components:
- Retrieval: Access to relevant information sources through vector search or structured queries
- Tools: Ability to interact with external systems via tools exposed through protocols like Model Context Protocol (MCP)
- Memory: Persistent knowledge from past interactions stored in graph structures
Context encompasses all the relevant background information, state, and relational knowledge that enables an agent to interpret inputs accurately. This includes:
- Immediate context: Current conversation history, user preferences, and task-specific parameters.
- Persistent knowledge: Domain facts, learned patterns, and historical interactions.
- Structural relationships: Connections between entities, concepts, and their semantic relationships (knowledge graphs).
- Environmental awareness: Current constraints, available tools, and system state.
The knowledge graph advantage
Knowledge graphs provide a powerful framework for organizing agent memory. Unlike traditional RAG systems that work with static, unstructured data, knowledge graphs capture semantic relationships between entities using a property graph model.
Consider this practical example from the webinar. When an agent receives: "Will works at Hypermode in developer experience. Kevin works at Hypermode and is the CEO," our example agent constructs a knowledge graph that represents this information:
Person(Will) --[WORKS_AT]--> Company(Hypermode)
Person(Will) --[HAS_ROLE]--> "Developer Experience"
Person(Kevin) --[WORKS_AT]--> Company(Hypermode)
Person(Kevin) --[HAS_ROLE]--> "CEO"This representation ensures that when the agent later encounters references to "Will" or queries about "who works at Hypermode," it can traverse the graph to find relevant context efficiently.
Technical implementation with Modus and Dgraph
The webinar demonstrated a concrete implementation using Modus (an open-source agent framework) and Dgraph (a distributed graph database).
Here's how the pieces fit together:
Agent memory example
Here's a simple example of an agent that maintains state and can process messages. The agent maintains a conversation history and can process messages to extract entities and update the graph.
This agent is orchestrated using Modus, an open-source agent framework that provides abstractions for creating agents including working with data, models, and tools.
Each agent has state which can be thought of as short-term memory. Our agent maintains a conversation history as state and can process messages to extract entities and update the graph.
// Each agent maintains state and can process messages
type ChatAgent struct {
agents.AgentBase
state ChatAgentState
}
type ChatAgentState struct {
ChatHistory string
}
// Messages trigger entity extraction and graph updates
func (c *ChatAgent) OnReceiveMessage(msgName string, data *string) (*string, error) {
switch msgName {
case "new_user_message":
return c.chat(data)
case "get_chat_history":
return &c.state.ChatHistory, nil
default:
return nil, nil
}
}Entity extraction and persistence
When processing natural language, the system:
- Extracts entities and their types (Person, Company, Event)
- Identifies relationships between entities
- Creates timestamped facts in the graph
- Maintains bidirectional relationships for efficient traversal
This allows the agent to maintain context over time and build up a knowledge base of facts about the world.
Graph query example
Querying the knowledge graph allows the agent to retrieve context relevant for responding to a specific user message by searching for specific entities and their relationships. Combining vector search with graph traversal is a powerful approach to retrieving relevant context for a specific user message using embeddings of the message.
This example knowledge graph query returns a list of facts, including the name, date created, date the fact happened on, and entity information.
query {
fact(func:has(fact)) {
name:fact
created_at
happened_on
entity:fact.entity {
name:entity.name
type:entity.type}
}
}This information is provided to the agent as context to help the model provide more accurate responses.
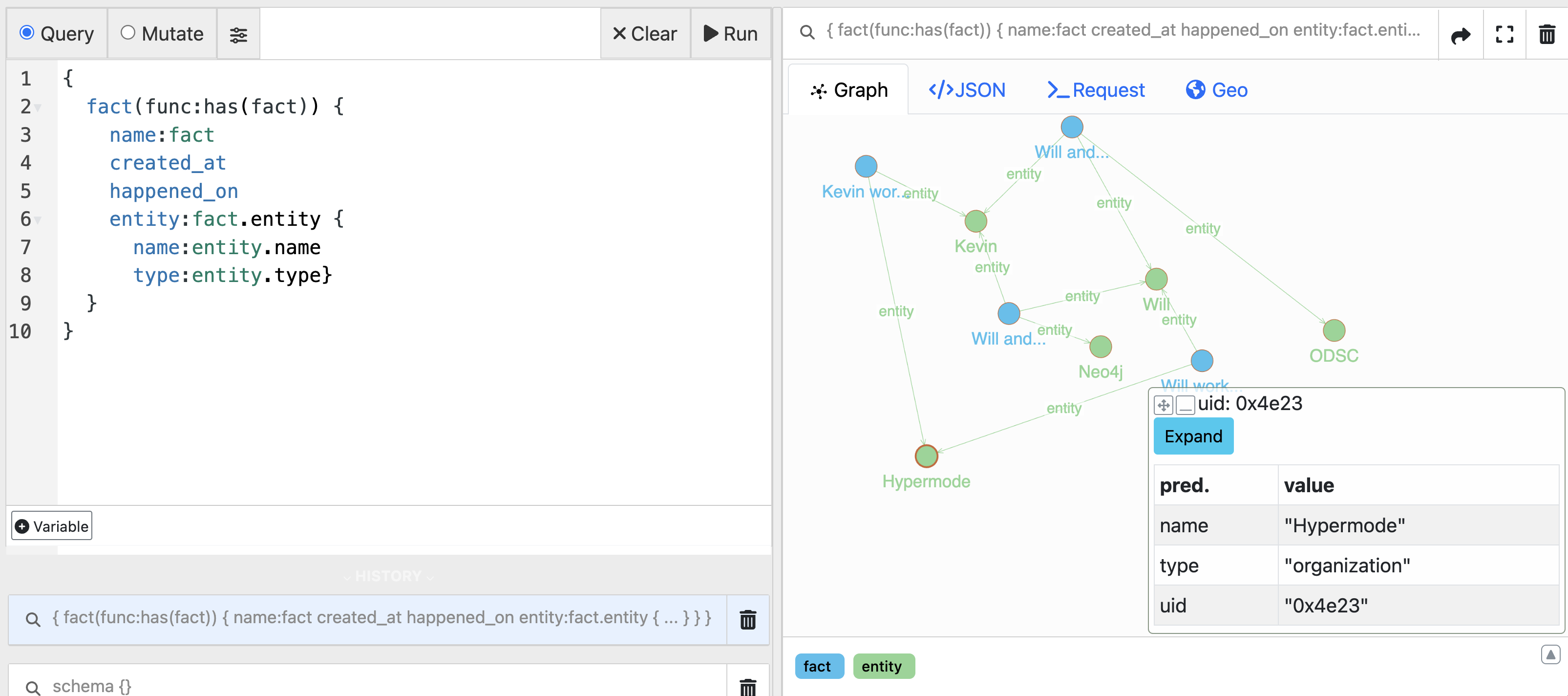
Here we can see the agent is able to retrieve context relevant for responding to a specific user message by searching for entities and their relationships.
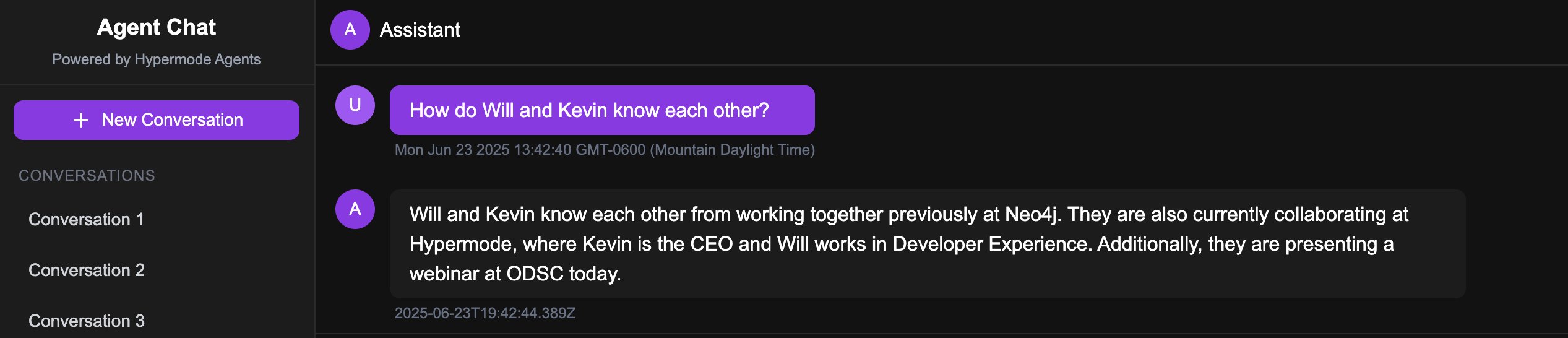
You can find the code for this example agent in the Modus Recipes GitHub repository.
Practical applications in production
Real-world implementations demonstrate the power of graph-based agent memory:
Entity Resolution: A pharmaceutical company uses knowledge graphs to automate clinical study design. The graph disambiguates entities like "Dr. Smith" vs "Smith Protocol" based on contextual relationships, ensuring trial protocols reference the correct entities.
Dynamic Context Building: Sales operations agents learn organizational nuance. When a specific person mentions "budget," the agent learns through graph relationships that they mean "allocated resources," building personalized understanding over time.
Multi-Agent Coordination: Through message passing in the actor model, specialized agents share discoveries. A technical documentation agent might update the graph with new API information, which the customer support agent can immediately access.
Scaling considerations
Memory management strategies
As agents accumulate interactions, several strategies keep the system performant:
- Time Decay: Recent memories are weighted higher using exponential decay functions
- Hierarchical Summarization: Older interactions are summarized into higher-level facts
- Index-Free Adjacency: Graph databases traverse relationships in constant time, regardless of graph size
Connection pooling and concurrency
When supporting thousands of concurrent agents, the Modus runtime handles:
- Database connection pooling to prevent overwhelming the graph database
- WebAssembly based sandboxing for secure, isolated agent execution
- Message passing for coordination without shared state
Building smarter agents: key technical principles
Some takeaways from lessons learned in building AI agents:
-
Graph schema design: Define clear entity types and relationships upfront. A well-designed ontology makes queries efficient and entity resolution accurate.
-
Hybrid Retrieval: Combine vector search (for semantic similarity) with graph traversal (for structured relationships). Use embeddings as entry points, then traverse for context.
-
Incremental Learning: Each interaction updates the graph. Agents become smarter not through retraining, but through accumulated contextual knowledge.
-
Tool Integration via MCP: Expose graph queries as tools agents can call. This allows agents to explicitly request specific context when needed.
-
State Management: Use actor model abstractions to maintain agent state across interactions while enabling horizontal scaling.
Many of these concepts drive the architecture, design, and implementation of Hypermode Agents and the open source Modus agent framework.
The path forward
The future of AI agents lies not in more sophisticated models alone, but in better memory systems that capture and utilize context effectively. By combining knowledge graphs with modern agent frameworks like Modus, we can create AI systems that truly understand their environment and learn from every interaction.
The tools demonstrated - Modus for orchestration, Dgraph for graph storage, MCP for tool integration - are available today as open-source projects and are the building blocks for Hypermode Agents which allows users to create domain specific agents from natural language instructions.
Give Hypermode Agents a try today by creating a free account and let us know what you think!