JANUARY 9 2025
Announcing Neo4j support for Modus
Building model-native apps with Neo4j knowledge graphs
AI has transformed how we build apps, but organizations need more than just large language models to create reliable, production-ready systems.
Today, the Hypermode and Neo4j teams are excited to announce Neo4j support in Modus, bringing the power of knowledge graphs to AI workflows.
Knowledge graphs address key limitations of standalone LLMs by providing semantic structure and domain-specific context that both humans and AI can reason with. While LLMs excel at natural language understanding, they can hallucinate or miss crucial details that are locked up in private enterprise-specific data silos. Knowledge graphs solve this dilemma by grounding AI outputs in verified facts and relationships, while making their reasoning process fully traceable.
By combining the graph capabilities of Neo4j with Modus, organizations can now build AI applications that leverage both broad language understanding and deep domain expertise. Whether validating AI outputs, incorporating proprietary data, or ensuring auditability, knowledge graphs provide the missing link between powerful language models and enterprise requirements.
Under the hood, we use Neo4j's Go driver in Modus. Thanks to the polyglot language support in Modus—powered by WebAssembly—we can support Neo4j in any language supported by Modus, which is currently Go and AssemblyScript.
Implementation
To stay production-ready, Modus creates and maintains drivers for Neo4j on app load, meaning connections are shared between function executions. This significantly reduces overhead, unlike existing serverless frameworks which require a new driver instance per function call.
Since the Neo4j SDK is using the Go driver under the hood, the function
signature and implementation resemble the driver's functions. Currently,
executeQuery is supported
by the Modus SDK, with plans to expand to more complex capabilities such as
transactions, sessions, and parallelization. The SDK also supports Neo4j types,
like Node, Relationship, and Path, along with functions to help deserialize
Cypher query responses
(getRecordValue, getProperty).
Getting started with Neo4j in Modus
Let's take a look at a hands-on example of using Neo4j and Modus. Our example Modus-Neo4j app will:
- Start with a sample Neo4j database of movies and movie reviews.
- Use Modus and an embedding model hosted by Hypermode to create embeddings for each movie and save those in Neo4j.
- Expose a GraphQL endpoint to find similar movies using Modus and Neo4j's vector search capability.
The easiest way to get started with Neo4j is by using the Neo4j Sandbox. Once you sign up for a free account, you'll be prompted to choose a dataset. We'll select the Recommendations dataset which includes data about movies and movie reviews.
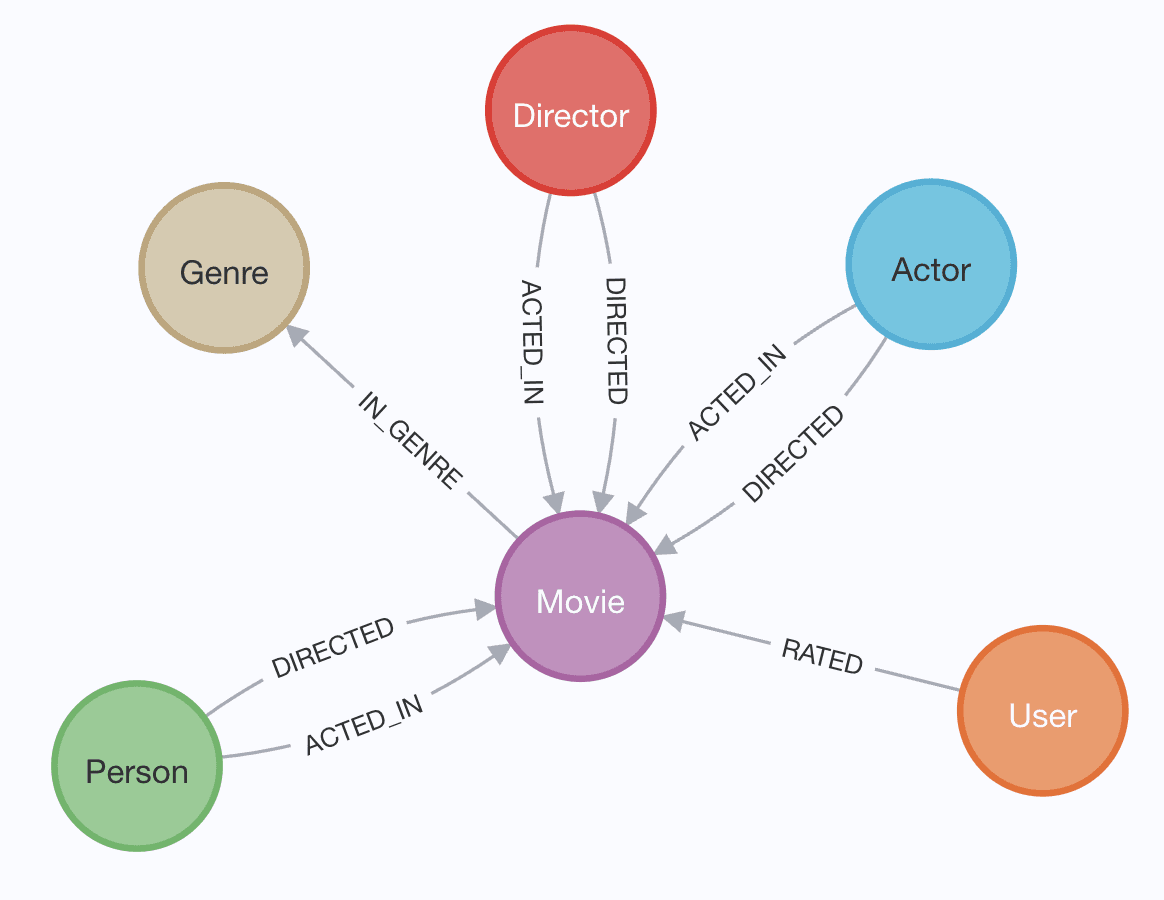
Below is the graph data model for this database. There are nodes with labels
like Movie, Actor, Genre, and User connected by relationships such as
IN_GENRE, ACTED_IN, and RATED.
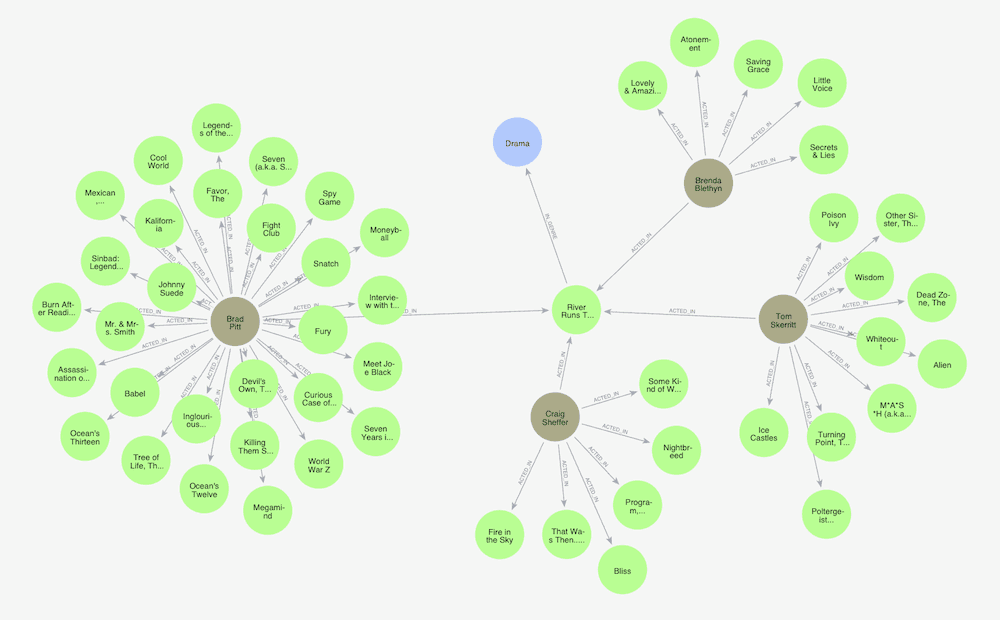
Neo4j uses a query language called Cypher that allows developers to specify connected data patterns to be searched in the graph. For example, if we wanted to search for a movie with the title River Runs Through It, A, its genre, and find what other movies the actors of A River Runs Through It also acted in, we would write a Cypher query like this:
MATCH (g:Genre)<-[ig:IN_GENRE]-(m:Movie)<-[a1:ACTED_IN]-(a:Actor)-[a2:ACTED_IN]->(other:Movie)
WHERE m.title = "River Runs Through It, A"
RETURN *The results below show our Movie node, the genre, and actors and their connections to the other movies in our database.
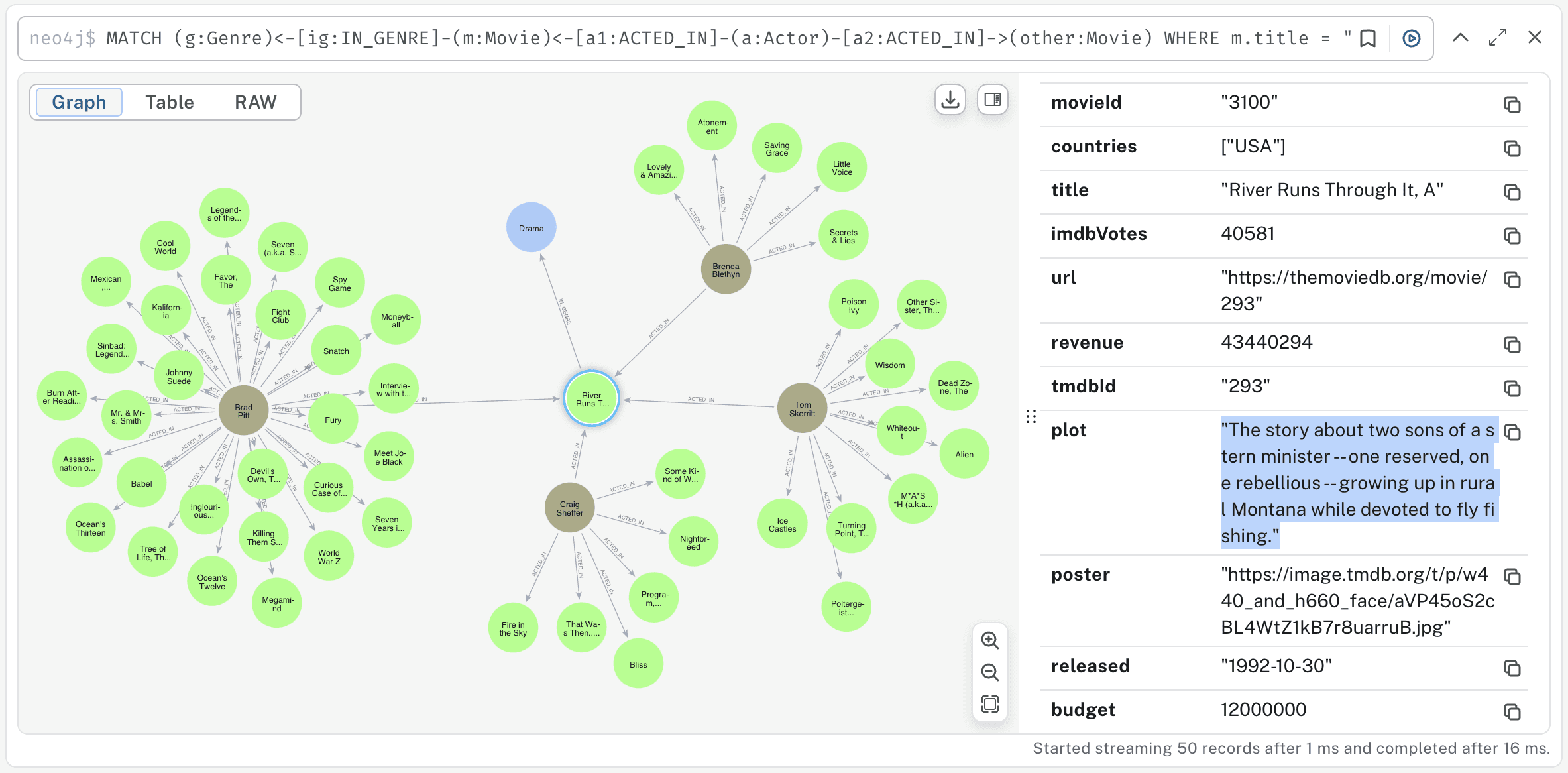
In addition to nodes and relationships, the property graph data model used by
Neo4j also allows for storing property values on each node and on each
relationship. Below you can see the properties stored on the Movie node
including movieId, title, and plot.
Using the preceding example, let's say you wanted to build a movie recommendation system. You could traverse the graph to find similar movies based on overlapping actors, genres, or a collaborative filtering type system that leverages user reviews. Another approach would be to create embeddings and use vector similarity search to find movies that are close together in vector space. We'll take a look at that next.
Vector search and embeddings
Vector embeddings transform content into numerical vectors that capture semantic meaning, allowing similar concepts to be discovered even without exact keyword matches. This enables vector search — instead of just basic keyword matching, you can find content based on conceptual similarity by measuring the distance between embedding vectors.
While powerful, vector search alone lacks understanding of data relationships and structure. By combining embeddings with knowledge graphs, you create a more intelligent search engine that leverages both semantic similarity and explicit connections. Queries first find semantically similar content through embeddings, then the queries traverse the graph to surface additional relevant information through relationships.
This hybrid approach delivers richer results by combining the semantic understanding of embeddings with the structured relationships of knowledge graphs. A product search can find relevant documentation through vector similarity, then traverse the graph to surface related products, components, and solutions. The result is a more comprehensive search that understands both meaning and relationships, with a clear explanation of how results are connected through the graph.
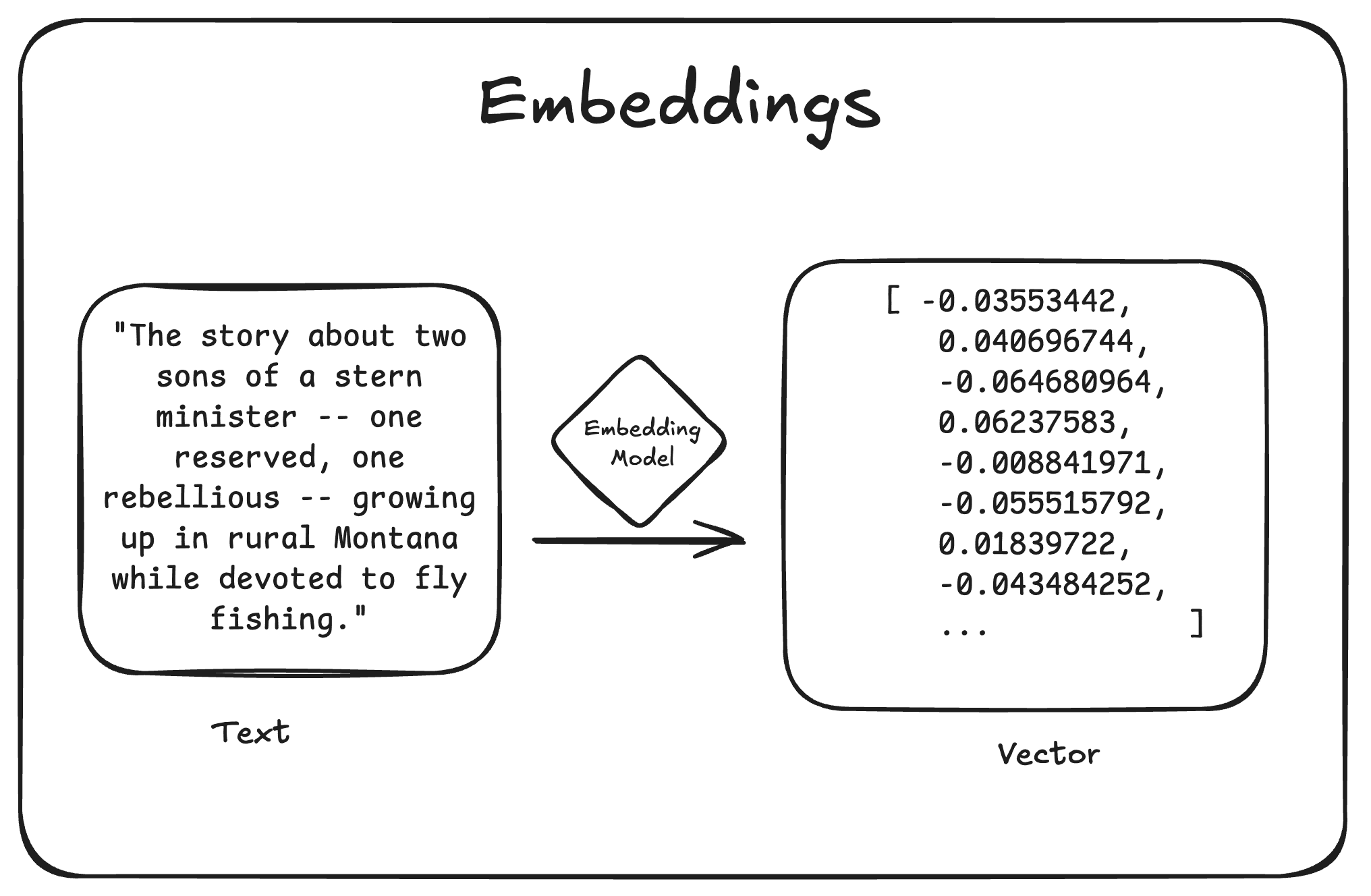
Neo4j supports vector search, which we can expose through a Modus function and a GraphQL API to enable searching for similar movies. We'll also use an embedding model hosted on Hypermode to generate embedding values based on the plot description of each movie.
Creating embeddings with Hypermode
To get started with Hypermode and Neo4j we'll create a new Modus project using
the modus new command. Be sure to install the Modus command-line tool if you
haven't already:
npm i -g @hypermode/modus-cliAfter creating the skeleton of our project we'll update our app manifest
modus.json file to
- Define a connection to our Neo4j Sandbox instance, using secret templates for the credentials that are read from environment variables
- Define a MiniLM model hosted on Hypermode to be used to generate embedding values.
Our modus.json file should look like this:
{
"$schema": "https://schema.hypermode.com/modus.json",
"endpoints": {
"default": {
"type": "graphql",
"path": "/graphql",
"auth": "bearer-token"
}
},
"models": {
"minilm": {
"sourceModel": "sentence-transformers/all-MiniLM-L6-v2",
"provider": "hugging-face",
"connection": "hypermode"
}
},
"connections": {
"neo4j": {
"type": "neo4j",
"dbUri": "{{NEO4J_URI}}",
"username": "{{USERNAME}}",
"password": "{{PASSWORD}}"
}
}
}The MiniLM embedding model is one of the shared models available with a Hypermode free trial.
Next, we'll need to find the connection credentials for our Neo4j Sandbox
instance and set them as environment variables in a .env file. We can find
these values in the Neo4j Sandbox app.
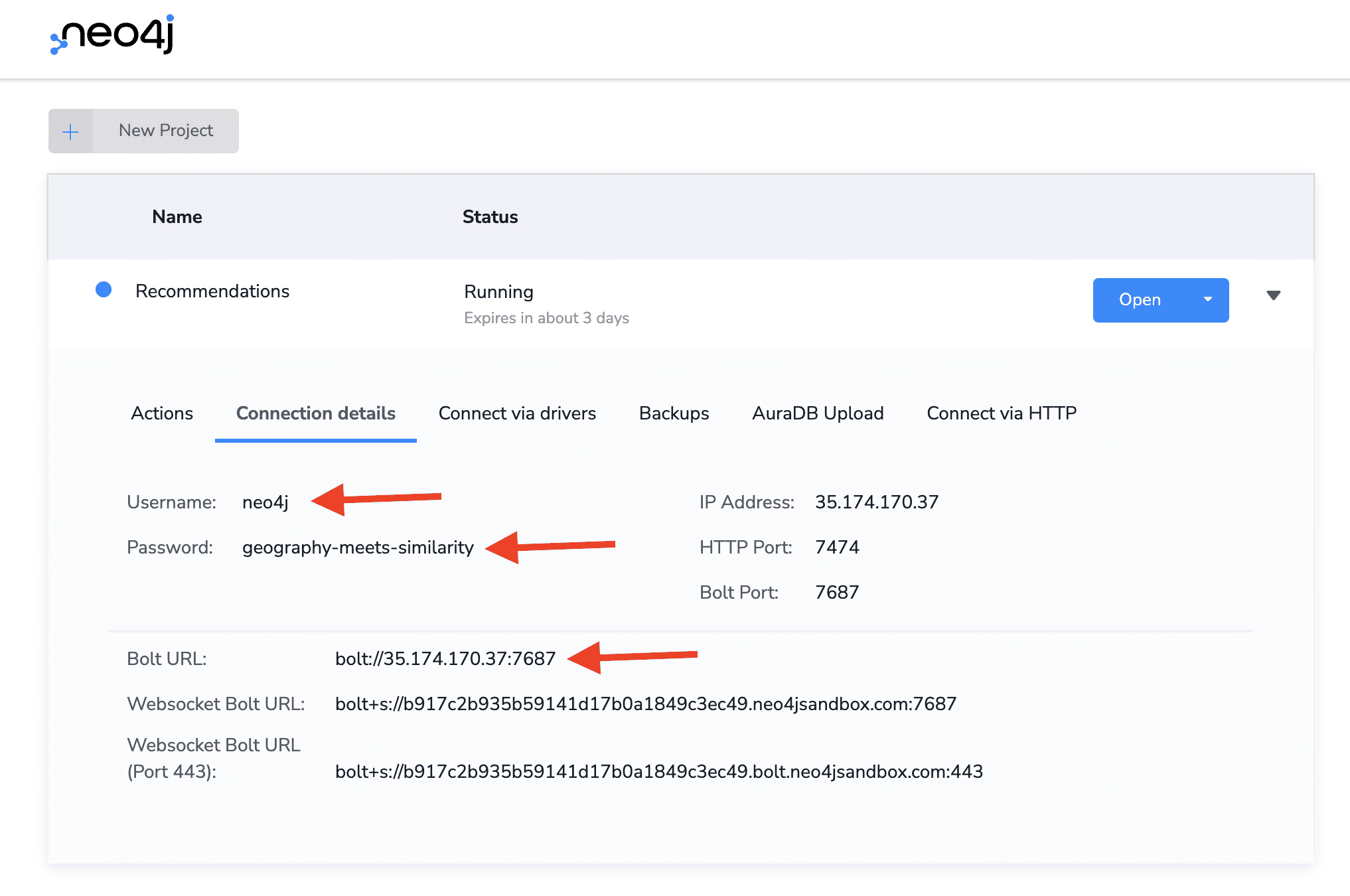
Then our .env file should have the following format (note that our environment
variables are namespaced by MODUS_ and the name of our connection (in this
case NEO4J).
MODUS_NEO4J_NEO4J_URI=bolt://35.174.170.37:7687
MODUS_NEO4J_USERNAME=neo4j
MODUS_NEO4J_PASSWORD=geography-meets-similarityNext, we'll create a helper function to invoke the MiniLM embedding model and generate embeddings.
// Create embeddings using the minilm model for an array of texts
export function generateEmbeddings(texts: string[]): f32[][] {
const model = models.getModel<EmbeddingsModel>('minilm')
const input = model.createInput(texts)
const output = model.invoke(input)
return output.predictions
}
If we run our Modus app locally with the modus dev command, our app is built
and a local GraphQL endpoint exposes this generateEmbeddings function as a
GraphQL query field. We can open a web browser at
http://localhost:8686/explorer to launch the Modus API Explorer and test this
endpoint locally.
To access Hypermode hosted models in the local development environment we'll
need to install the hyp command-line tool and sign in to a Hypermode free
trial account.
npm i -g @hypermode/hyp-cli
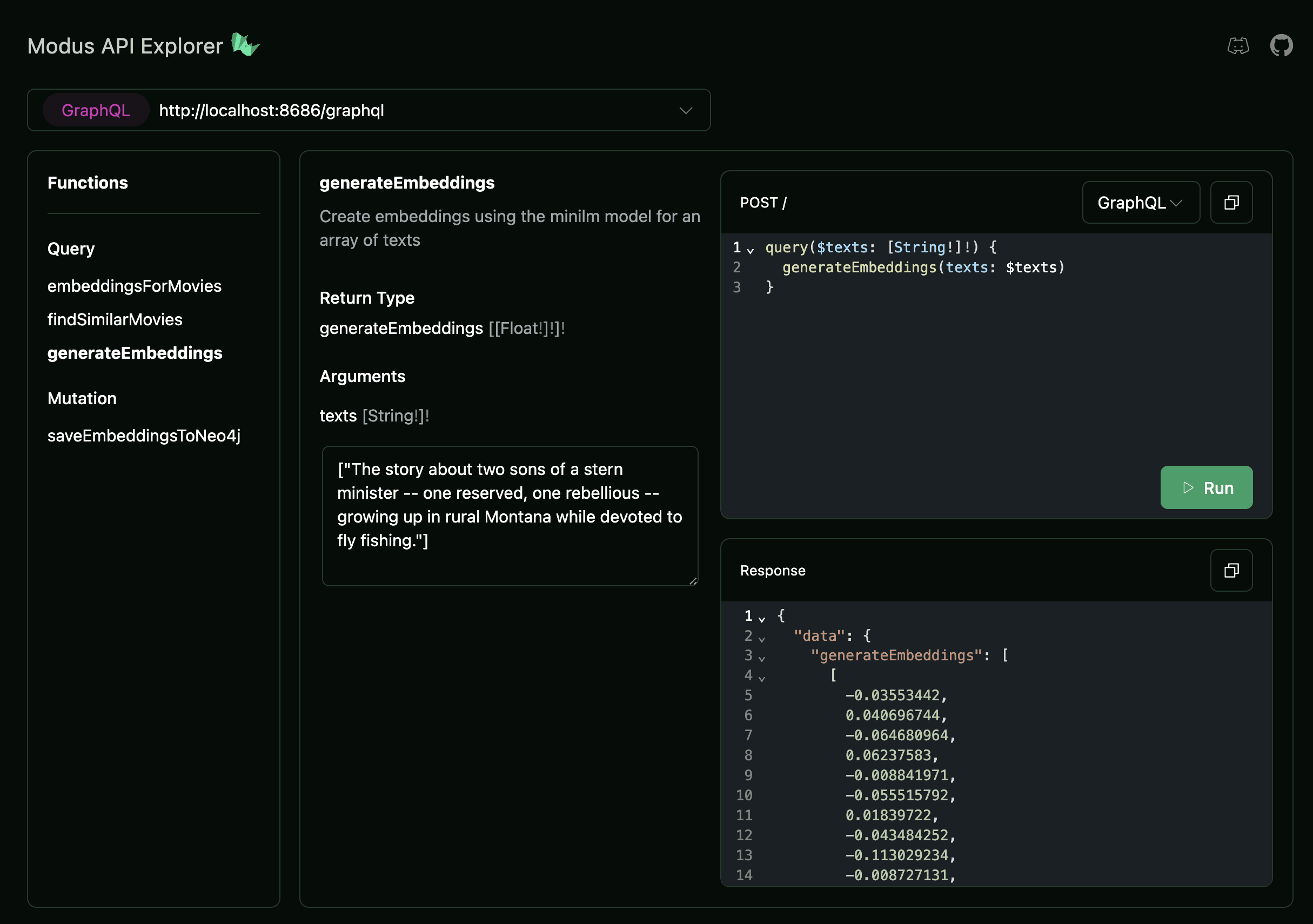
hyp loginOnce we sign in to Hypermode via the hyp command-line tool we can invoke the
MiniLM model via our GraphQL API. Here, as you can see below, we generate
embeddings for a single string, one of the movie plots.
We can use this function we just defined, combined with the Neo4j client in Modus, to:
- Retrieve the movie plot values
- Compute embeddings
- Write those values back to Neo4j as a new
embeddingnode property - Create a vector index in Neo4j
First we'll define a type to represent our movie nodes.
@json
export class Movie {
id!: string
title!: string
plot!: string
rating!: f32
embedding: f32[] = []
constructor(id: string, title: string, plot: string, rating: f32) {
this.id = id
this.title = title
this.plot = plot
this.rating = rating
this.embedding = []
}
}Next, we'll create a new function saveEmbeddingsToNeo4j to find movies without an embedding value, generate embedding values using the movie plot property, write back to Neo4j and create a vector index.
// Update movie nodes in Neo4j with generated embeddings and create a vector index
export function saveEmbeddingsToNeo4j(count: i32): i32 {
const query = `
MATCH (m:Movie)
WHERE m.embedding IS NULL AND m.plot IS NOT NULL AND m.imdbRating > 0.0
RETURN m.imdbRating AS rating, m.title AS title, m.plot AS plot, m.imdbId AS id
ORDER BY m.imdbRating DESC
LIMIT toInteger($count)`
const countVars = new neo4j.Variables()
countVars.set('count', count)
const result = neo4j.executeQuery(hostName, query, countVars)
const movies: Movie[] = []
// Here we iterate through each row returned and explicitly access each column value
// An alternative would be to return an object from the Cypher query and use JSON.parse to handle type marshalling
// see findSimilarMovies function below for an example of this approach
for (let i = 0; i < result.Records.length; i++) {
const record = result.Records[i]
const plot = record.getValue<string>('plot')
const rating = record.getValue<f32>('rating')
const title = record.getValue<string>('title')
const id = record.getValue<string>('id')
movies.push(new Movie(id, title, plot, rating))
}
// Batch calls to embedding model in chunks of 100
const movieChunks: Movie[][] = []
for (let i = 0; i < movies.length; i += 100) {
movieChunks.push(movies.slice(i, i + 100))
}
for (let i = 0, len = movieChunks.length; i < len; i++) {
let movieChunk = movieChunks[i]
// Generate embeddings for a chunk of movies
const embeddedMovies = getEmbeddingsForMovies(movieChunk)
// Update the Movie.embedding property in Neo4j with the new embedding values
const vars = new neo4j.Variables()
vars.set('movies', embeddedMovies)
const updateQuery = `
UNWIND $movies AS embeddedMovie
MATCH (m:Movie {imdbId: embeddedMovie.id})
SET m.embedding = embeddedMovie.embedding
`
neo4j.executeQuery(hostName, updateQuery, vars)
}
// Create vector index in Neo4j to enable vector search on Movie embeddings
const indexQuery =
'CREATE VECTOR INDEX `movie-index` IF NOT EXISTS FOR (m:Movie) ON (m.embedding)'
neo4j.executeQuery(hostName, indexQuery)
return movies.length
}We can invoke this saveEmbeddingsToNeo4j function via the Modus API Explorer.
The function takes a count value to specify the maximum number of movies we
want to update embedding values for, in batches of 100 at a time.
Now we're ready to find similar movies using vector search!
First, we'll define a class for our movie search results which includes a score that represents how similar our movie results are in vector space.
// Results of a movie search, includes movie details and a similarity score
@json
export class MovieResult {
movie!: Movie
score: f32 = 0.0
constructor(movie: Movie, score: f32) {
this.movie = movie
this.score = score
}
}And now we'll create a new function findSimilarMovies to search for similar
movies using vector search given a movie title. Note that the Cypher query in
this function returns an object which we can then directly marshal into an array
of MovieResult objects using JSON.Parse.
// Given a movie title, find similar movies using vector search based on the movie embeddings
export function findSimilarMovies(title: string, num: i16): MovieResult[] {
const vars = new neo4j.Variables()
vars.set('title', title)
vars.set('num', num)
const searchQuery = `
MATCH (m:Movie {title: $title})
WHERE m.embedding IS NOT NULL
CALL db.index.vector.queryNodes('movie-index', $num, m.embedding)
YIELD node AS searchResult, score
WITH * WHERE searchResult <> m
RETURN COLLECT({
movie: {
title: searchResult.title,
plot: searchResult.plot,
rating: searchResult.imdbRating,
id: searchResult.imdbId
},
score: score
}) AS movieResults
`
const results = neo4j.executeQuery(hostName, searchQuery, vars)
let movieResults: MovieResult[] = []
if (results.Records.length > 0) {
const recordResults = results.Records[0].get('movieResults')
movieResults = JSON.parse<MovieResult[]>(recordResults)
}
return movieResults
}
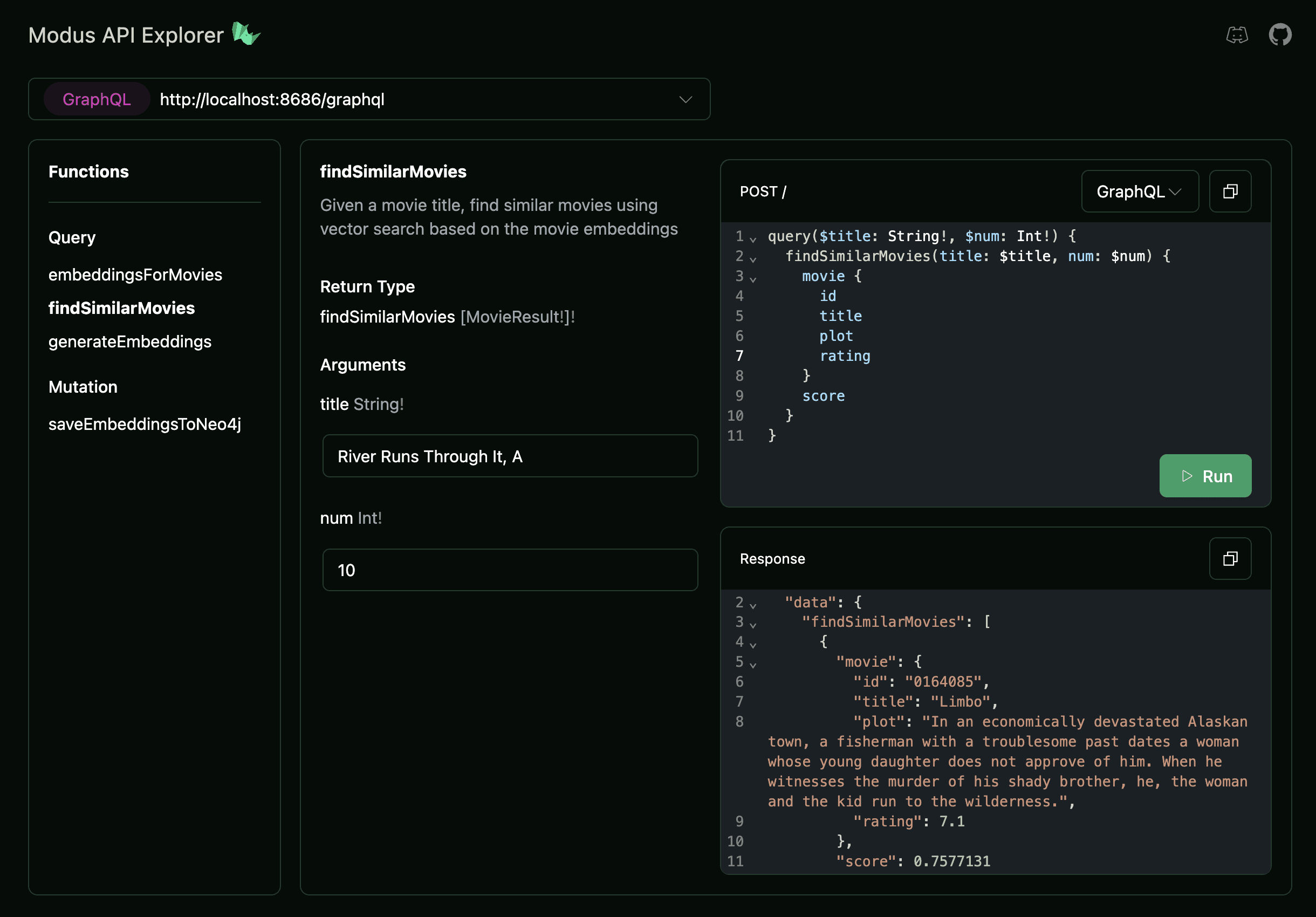
Now we search for similar movies using this Query field in the Modus API Explorer.
Now that everything is working locally, the next step would be to deploy our Modus app to Hypermode, which we can do using a Hypermode free trial, and then build a front-end app to make a true movie search engine. I'll leave both of those steps as an exercise for next time. :-)
Resources
Conclusion
I hope you've found this walkthrough helpful.
We're excited to see what you build with the new Neo4j support now available for Modus. Integrating knowledge graphs into your AI workflows isn't always straightforward, but now it's a little easier.
Keep up with every new feature and release in Modus: Star the Modus GitHub repository to stay in the loop with every new feature we ship.