AUGUST 27 2024
Pick Your Packer: Building Intelligent Search with Modus and Dgraph
Pick Your Packer and Hypermode teams share technical details about natural language search on top of Dgraph.
Pick Your Packer (PYP) is “Zillow for Food and Beverage.” They’ve built an easy-to-use platform for connecting food and beverage co-manufacturers and ingredient suppliers worldwide.
PYP is about helping creators discover their perfect supply partners. This case study explores how Pick Your Packer built Google-quality search using Modus on top of their Dgraph database.
Searching in Dgraph
PYP uses Dgraph to store information about food and beverage co-manufacturers and ingredient suppliers. A graph database is well suited to capture highly-connected, highly-variable data. Dgraph’s lightweight schema allows the team to iterate as the data complexity grows.
To illustrate their approach let’s consider a simplified data model:
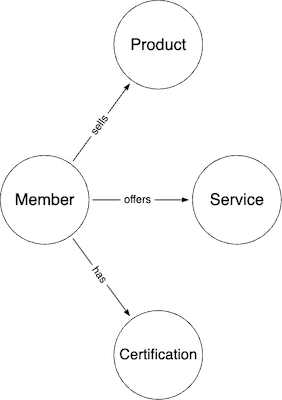
In Dgraph, this model can be easily implemented by a GraphQL schema:
type Member {
name: String @id
products: [Product]
services: [Service]
}
type Product {
productID: ID
name: String @id @search(by: [term])
otherProductAttribute: String
}
type Service {
serviceID: ID!
name: String @id @search(by: [term])
otherServiceAttribute: String
}The additional directive @search(by: [term]) used on names, instructs Dgraph
to index those attributes and provides developers with powerful functions
allofterms or anyofterms to search by terms.
For example, finding Members producing any product whose name contains the
term almond is easily done by a GraphQL query using the @cascade directive
in Dgraph:
query MyQuery {
queryMember(first: 10) @cascade {
products(filter: { name: { anyofterms: "almonds" } }) {
name
}
name
}
}This is the basis used to implement a keyword search.
Going Beyond Keyword Search
Keyword search is often a disappointing and unintuitive experience for users. It would be terrible if you were looking for “limes” but get no results because the suppliers you need are classified under “citrus.” To make the platform more intuitive and user-friendly, Pick Your Packer introduced natural language queries, also known as “semantic search.”
Here are a few examples of challenges introduced by natural language queries:
-
"Do you know anyone producing almonds?" The sentence is not limited to some keywords. We need to locate the relevant information to query the database amid the potentially complex sentence.
-
"Looking for nuts and fruits": 'Apples' should match 'fruits' and 'almonds' should match 'nuts'. That's exactly where term search is falling short. We need some semantic similarity.
-
"Who is producing nuts, offering co-packaging and is FDA certified?" Users may use multiple search criteria in the same sentence. We need to be able to perform a level of 'entity resolution': which part is about a product or a service in the sentence?
Augment Dgraph with Modus AI functions
Let's see how to improve the search capability. We will illustrate the approach
for Products.
Step 1: Add Vector Embeddings
The first step is to add a new predicate to the Product type and deploy the
updated schema. Dgraph is doing a hot deployment, the operation is
straightforward and does not require any data migration.
type Product {
name: String @id @search(by: [term])
otherProductAttribute: String
embedding: [Float!] @embedding @search(by: ["hnsw"])
}Step 2: Compute Embeddings
The second step consists of computing the vector embedding for all Products.
The logic is done in Modus: Modus makes it easy to declare AI models and use them for inference tasks. Modus also provides connections and functions to query databases including Dgraph, either in GraphQL or in native DQL.
We have several options here:
- expose 'addProduct' and 'updateProduct' API from Modus and compute the embedding in the function logic.
- create an embedding synchronization API that computes and stores the vectors
for all
Productwithout embedding. - invoke an embedding function created in Modus every time we detect an update on a Product using Dgraph lambda webhooks,
We have opted for the synchronization API.
Creating an API in Modus is as simple as exporting a function.
export function computeProductEmbeddings(): string {
/*
loop over all products without embeddings, compute and mutate embedding predicate
check if the loop is reaching new products else exit
*/
let lastFirstEntity: Entity | null = null;
while (true) {
const product_without_embeddings = getProductWithoutEmbeddings("dgraph-grpc");
// return first 100 products without embeddings
if (product_without_embeddings.length == 0) {
break;
}
addEntityEmbeddings(product_without_embeddings)
if (lastFirstEntity != null && lastFirstEntity.id == product_without_embeddings[0].id) {
// we are not making progress, something is wrong in the addEntityEmbeddings function
// abort to avoid infinite loop
throw new Error("No progress in adding embeddings")
}
lastFirstEntity = product_without_embeddings[0];
}
return "Success"
}Modus makes it easy to use embedding models to compute vectors from text, the
addEntityEmbeddings function invokes an embedding model service and executes a
mutation in Dgraph:
export function addEntityEmbeddings(entities: Entity[]): void {
const sentences = entities.map<string>((entity) => entity.title);
const uids = entities.map<string>((entity) => entity.uid);
const model = models.getModel<EmbeddingsModel>("minilm");
const input = model.createInput(sentences);
const output = model.invoke(input);
mutateEmbeddings("dgraph-grpc", uids, output.predictions, "Product.embedding");
}
The connections "dgraph-grpc", and AI models "minilm" used by the functions
are simply declared in a manifest file(modus.json). In our case, we have a
connection to the Dgraph cluster, and we are using a model from Hugging Face
called “minilm”:
# modus.json file extract
{
...
"models" : {
"minilm":{
"sourceModel": "sentence-transformers/all-MiniLM-L6-v2",
"host": "hypermode",
"provider": "hugging-face"
}
},
"hosts": {
"dgraph-grpc": {
"type": "dgraph",
"grpcTarget": "xyz.us-east-1.aws.cloud.dgraph.io",
"key": "{{API_KEY}}"
}
},When deployed on Hypermode, a private instance of the declared models is automatically cloned and hosted by Hypermode. Any function exported in your index.ts file is deployed and exposed as a GraphQL API. API keys for the different connections are set by administrators in the console.
The client application simply invokes computeProductEmbeddings GraphQL
operation to compute all missing embeddings.
With embeddings in place, we can use the GraphQL query
queryProductByEmbedding. This operation is automatically created by Dgraph
when deploying the Product type containing an embedding predicate.
Step 3: Sentence Analysis Logic
Because we’re dealing primarily with search inputs, we decided to find the
mentions of entities (Product, Service, ...) in the sentence rather than
analyzing the sentence grammar to ‘understand’ the query. In that sense, our
approach can be seen as an 'entity extraction' task.
Starting with a sentence such as "who produces fruits", we want to detect if
the sentence mentions some products from our product list.
Product names have one, two, or three words (e.g "nuts", "roasted nuts", "Kaffir Lime Leaves")
An N-gram is a sequence of n words from the sentence. The idea is to evaluate all possible 1-grams, 2-grams, and 3-grams. For example our query will lead to the list
"who", "who produces", "who produces fruits", "produces", "produces fruits" and "fruits".We have 3 x w - 3 possibilities for sentences with w words (w >= 3).
For each N-gram, we compute a vector embedding and search for similar products using a similarity threshold. We also give precedence to 3-grams over 2-grams and 1-grams: if we have a good match for the 3-grams we ignore the other matches, i.e a search for "roasted nuts" will use "roasted nuts" similarity and not "nuts".
As Dgraph + Modus offers a very efficient vector search and search queries are usually terse, the approach is fast enough.
The output of this step is a list of existing Products close to a part of the
sentence. For example "preserved fruits" or "banana" may match the part
'fruits'.
Step 4: Expose a New API
The logic to identify similar existing products in the user sentence is implemented as a Modus function. The logic is as follows:
export function recognizeProducts(
text: string,
cutoff: f32,
): RecognizedEntity[] {
// Get all the n-grams
const ngrams = createNgramList(text.toLowerCase());
// get embeddings for all terms
const model = models.getModel<EmbeddingsModel>("minilm");
const input = model.createInput(ngrams);
const output = model.invoke(input);
const embeddingList = output.predictions;
<PSEUDO CODE>
For each n-gram
- find similarProductByVector(n-gram vector) that are close enough (apply a threshold)
- if we have a match, remove 'lower' n-grams: for example if 'roasted nuts' matched then remove 'nuts' from the list of n-grams to test.
- add entities to the list of matching entities with the similarity score.
return the list of entities ordered by similarity score
</PSEUDO CODE>
}As mentioned, it is readily available as a GraphQL API for the client application.
Step 5: Update the client query
The client application can now obtain a list of Products candidates from the
user query. We can apply the confidence threshold as all matches are associated
with the similarity score.
The client app can use the Dgraph @cascade directive in GraphQL, and provide the list of ProductIDs to search for.
query queryMember{
queryMember @cascade {
products(filter: {productID: [<list of productIDs>]}) {productID}
name
}
}
@cascade turns the query into a pattern matching condition: this query will
find all Members with a relation to at least one of the given Product.
By doing the same for Services, we can now expose a unified search API.
Conclusion
Fuzzy matching and NLP have always been big topics in search and discovery tasks. They’re often at odds with traditional databases that rely on keys and indexes.
Dgraph stores data in an intuitive structure. More specifically, we naturally think about things based on how they relate to other things. Humans think in graphs. Relational databases are great for aggregations and direct lookups. However, they struggle to model and query for complex relationships. Dgraph is made to handle the “relationship” in your data.
Modus, is an open source serverless framework for building intelligent APIs, powered by WebAssembly. Modus gives Dgraph superpowers. When paired together, users have great flexibility to leverage models, implement complex chains of logic, and expose intelligent APIs.
By simply adding vector embeddings to an existing Dgraph cluster and writing AI logic in Modus to convert text into “embeddings”, analyze user inputs, and evaluate semantic similarities, PYP offers customers an intuitive and powerful “AI-search”.
About Pick Your Packer
Pick Your Packer is revolutionizing the B2B food and beverage industry by creating a comprehensive platform that connects manufacturers, suppliers, and distributors.