AUGUST 15 2025
MCP Powered Agents For Your Graph Database
Using Hypermode Agents and Neo4j MCP to build agents with knowledge graphs
Imagine having a conversation with an AI assistant that not only remembers what you discussed yesterday, but can also connect those memories with insights from your team members' conversations. Picture an agent that can seamlessly pull data from your GitHub repositories, understand the relationships between your projects, and automatically build a knowledge graph that reveals patterns you never noticed. This is what becomes possible when we combine Hypermode Agents and the Model Context Protocol (MCP) with graph databases like Neo4j.
In a recent episode of Hypermode Live, Michael Hunger from Neo4j and Will from Hypermode demonstrated how Hypermode Agents and MCP can be used to build agents that can work with knowledge graphs in Neo4j. Let's explore why this matters and how you can start building these capabilities yourself.
Understanding the foundation: Why integration has been so hard
Before we dive into the solution, it's worth understanding the problem that MCP solves. Think about how you use different tools throughout your workday—you might start in Slack, move to GitHub, check your calendar, update a spreadsheet, and search through documentation. Each of these tools has its own API, its own way of organizing data, and its own authentication system.
Now imagine trying to build an AI agent that could work across all these systems. Traditionally, every agent framework had to build individual integrations for each service they wanted to support. Neo4j, for example, had to create separate connectors for different agent platforms. Meanwhile, each agent framework was duplicating efforts, building their own integrations for the same databases and APIs that other frameworks were also connecting to.
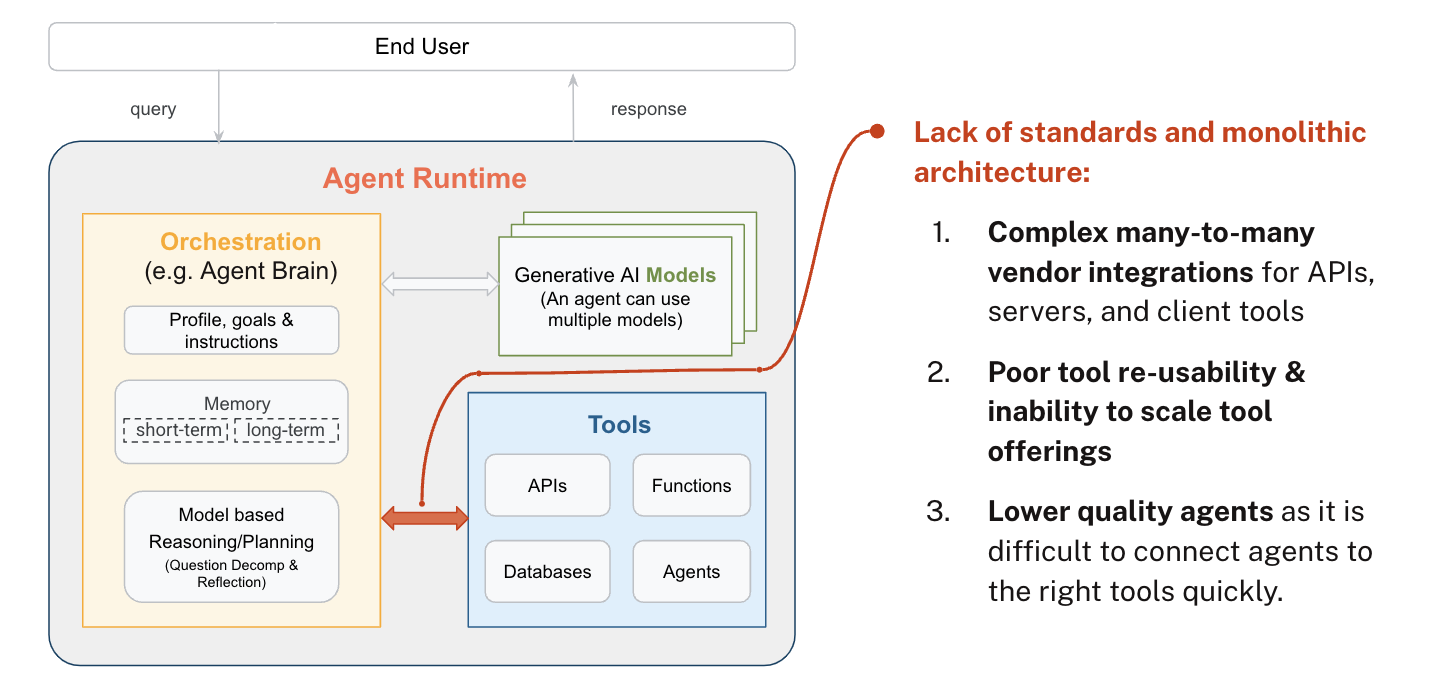
This created what developers call an "n plus one" problem—instead of building one integration that everyone could use, we were building n times n integrations, where every framework needed its own connector to every service. The result was inconsistent quality, wasted development effort, and tools that couldn't be shared across different platforms.
MCP: A universal language for AI tools
Anthropic's Model Context Protocol addresses this challenge by creating what Michael Hunger aptly describes as "the USB-C port for agentic applications." Just as USB-C allows any device to connect to any compatible port regardless of manufacturer, MCP creates a standard way for AI agents to connect to any service or database.
As Michael explained during the demonstration, "it standardizes how tools plug into agentic systems." This standardization means that "the capabilities of a server are made available in a way to the agent that it's easy for the LLM to pick and choose tools that are relevant for executing the tasks and then get the responses back from these tools."
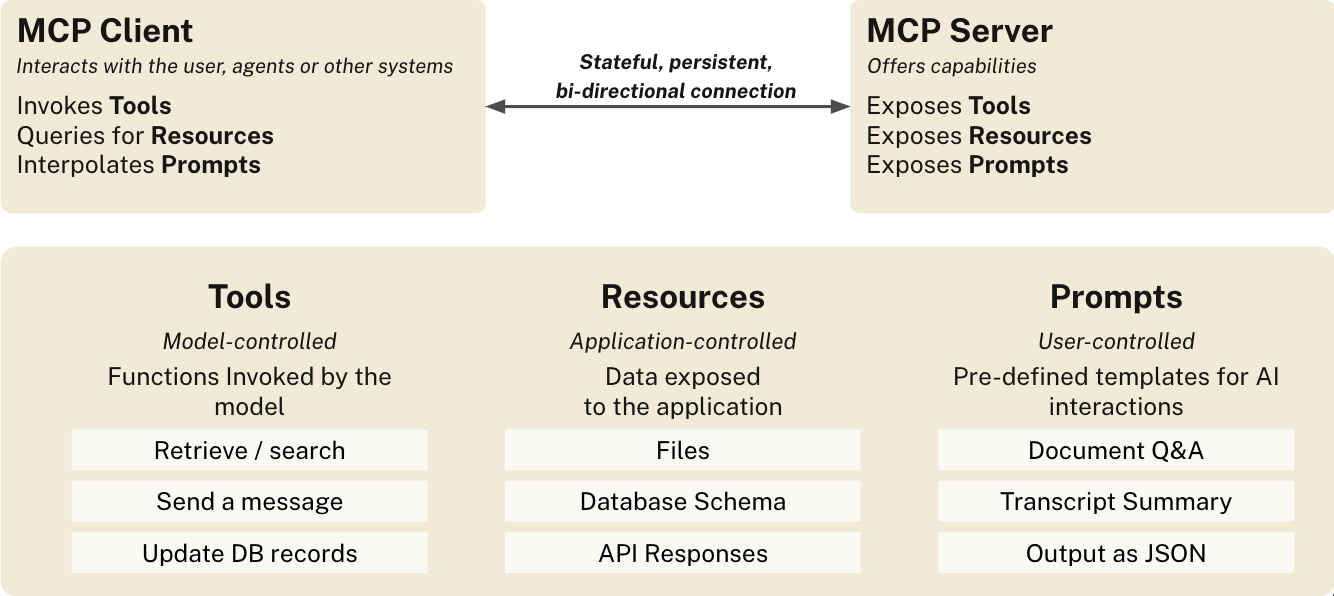
To understand how MCP works, think of it as having three main components, each serving a different purpose in the agent's toolkit:
- Tools are like remote function calls that agents can invoke—imagine being able to tell your agent "query the database" or "send this message" and having it know exactly how to do that
- Resources are more like reference materials—static information such as documentation, file contents, or database schemas that the agent can consult when it needs context
- Prompts are instructions that guide the AI on how to use these tools effectively, almost like having a user manual that teaches the agent the best practices for working with a particular service
The beauty of this approach is that once an MCP server exists for a service, any MCP-compatible agent can use it immediately. Neo4j builds one MCP server, and suddenly every agent framework that supports MCP can work with Neo4j databases. This dramatically reduces the integration burden and improves the quality of tools since developers can focus on building one excellent integration rather than many mediocre ones.
Building shared conversational memory in a knowledge graph
Michael and Will showed how two separate AI agents—running in different Claude Desktop instances—could share and build upon the same knowledge graph stored in Neo4j using the Neo4j memory MCP server.
Both Michael and Will connected their Claude instances to the same Neo4j database using the Neo4j memory MCP server. When they first queried what memories were stored, the agent responded that the database was empty—a blank slate waiting to be filled.
Creating the First Memories: Michael started by sharing a webpage about their livestream event. The agent automatically analyzed the content and began creating entities and relationships in the graph. As Michael described it, "it basically creates entities and relationships using the memory tools." The agent didn't just store text—it understood that there was an event, that Michael and Will were co-hosts, that they worked for different companies (Neo4j and Hypermode), and that these companies were collaborating on technologies.
Real-Time Collaboration: The magic happened when Will, from his separate Claude instance, asked "what memories do you have?" His agent immediately responded with the complete knowledge graph that Michael had just created, including the livestream event, the co-hosting relationship, and the company connections. This demonstrated true shared intelligence—knowledge created by one person's interaction with AI became immediately available to another.
Incremental Knowledge Building: Will then added more information: "update my memory to include more information about Will. He was just on vacation and traveled to Glacier Park. He works on developer experience at Hypermode." The agent recognized that Will was already in the graph and simply added new observations and relationships to his existing node. When Michael refreshed his view of the graph, he could see all the new information about Will's vacation and role.
What made this demonstration particularly powerful was seeing how natural it felt. Neither Michael nor Will had to explicitly tell their agents to "save this to the database" or "create a relationship between X and Y." The agents understood the context and automatically structured the information as a graph.
Using Hypermode Agents to read memories from the graph
Next, Will used Hypermode Agents to read memories from the graph. The first step was creating a new agent. Building agents in Hypermode is as simple as writing a few basic phrases to describe the agent's purpose, then the Hypermode agent builder generates a well structured agent system prompt to define the agent's role, background, and capabilities.
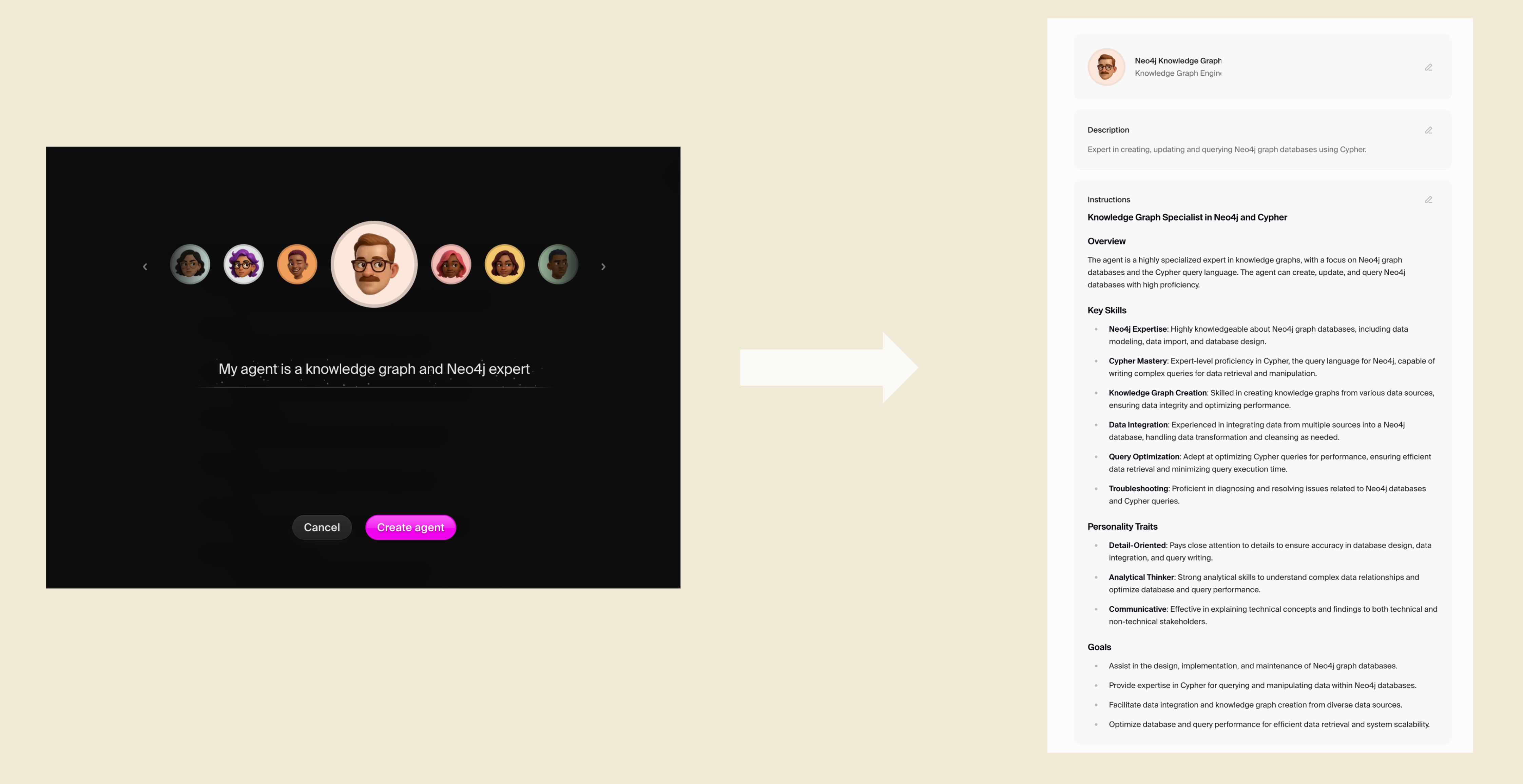
After creating the agent, the next step was to connect it to the Neo4j database using the Neo4j Hypermode Agent connection. We can then use natural language to query the graph.
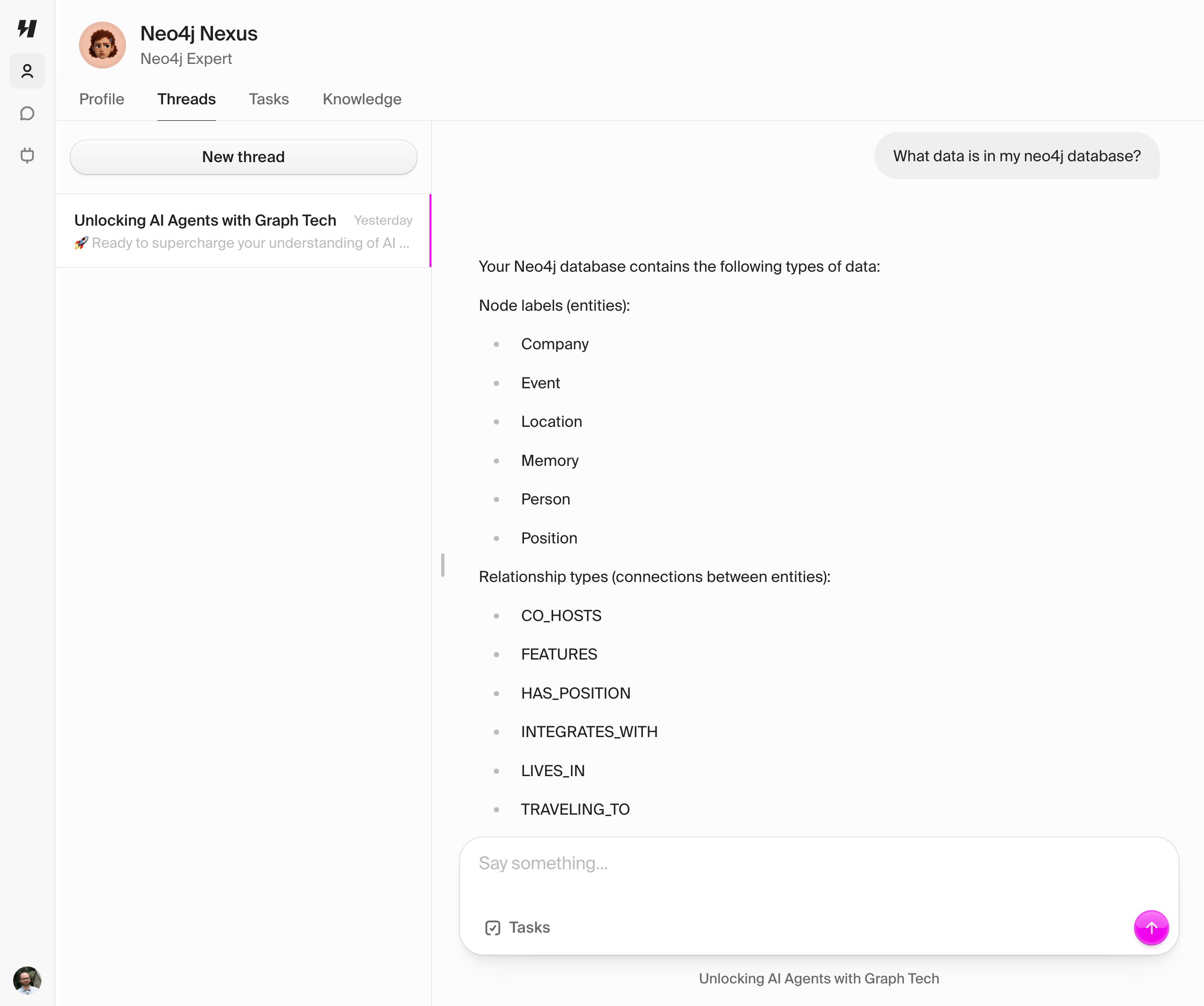
Will then showed how the knowledge graph could be used for practical content generation, illustrating the value of having rich, interconnected data available to AI agents.
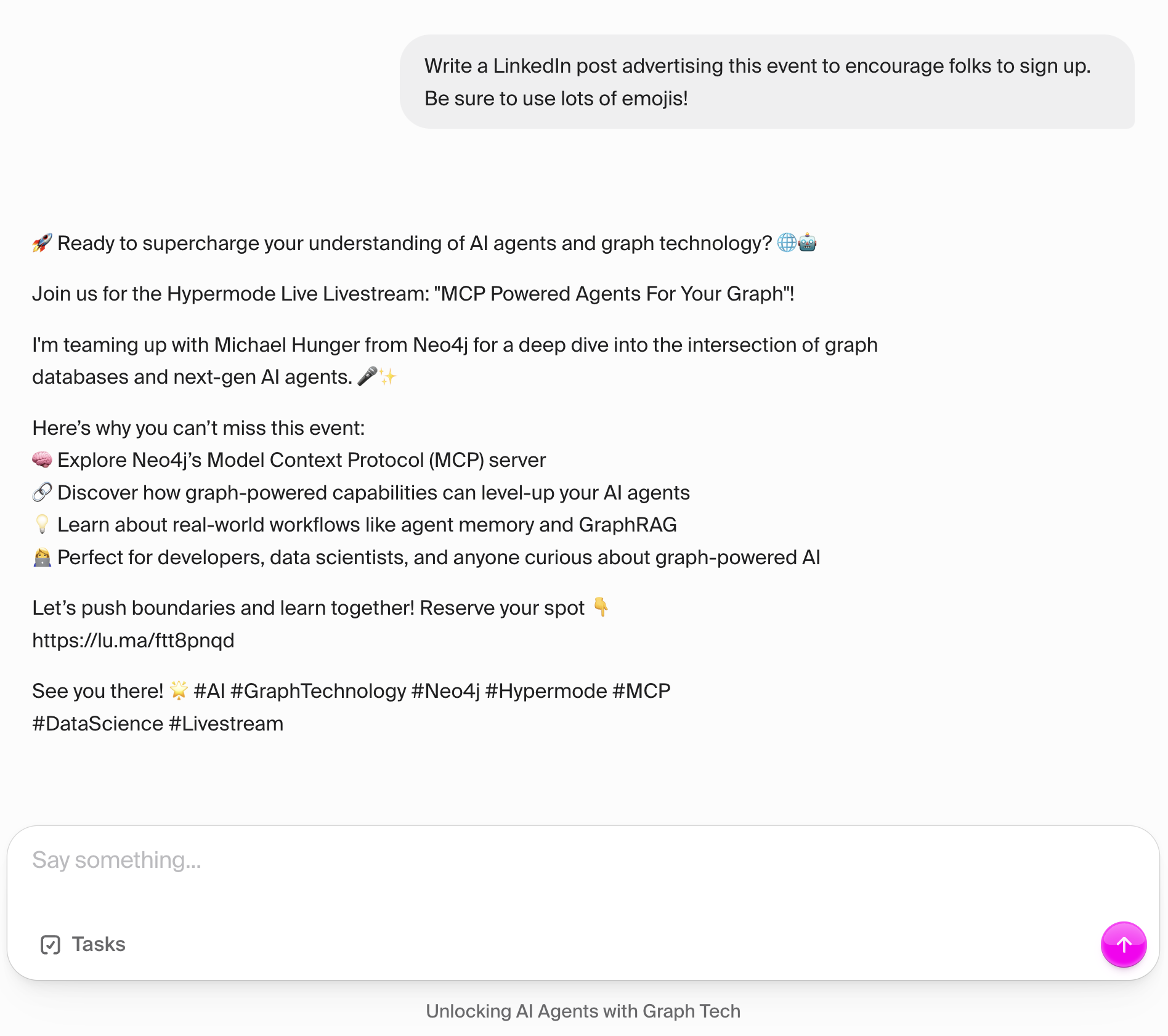
Leveraging Graph Relationships: Using the shared knowledge graph they had built earlier, Will asked his agent to "write a LinkedIn post, with a lot of emojis, advertising this event to encourage folks to sign up." The agent didn't just generate generic content—it drew specific information from the graph about the event, the co-hosts, their companies, and the technologies they were discussing.
Following Best Practices: As Will noted, "What's nice that I found in this sort of like helping you write social media posts is it follows best practices. It knows like how long they're supposed to be." The agent automatically formatted the post with appropriate emoji headers, bulleted content that would expand below the fold, and relevant hashtags—all standard LinkedIn best practices.
Contextually Rich Content: The generated post wasn't just factually accurate; it was contextually rich because the agent understood the relationships in the data. It knew that Michael worked for Neo4j, Will worked for Hypermode, that they were collaborating on MCP technologies, and that this was part of a livestream series. This contextual understanding allowed it to create content that felt natural and well-informed.
Visual Graph Exploration: Michael also demonstrated using Claude to generate interactive visualizations of the knowledge graph. By asking the agent to "read the data from the graph and then generate an artifact," he got a D3.js-based interactive graph visualization that showed all the entities and relationships they had created, making the abstract concept of a knowledge graph tangible and explorable.
The content generation demonstration highlighted how having structured, relationship-rich data available to AI agents enables them to create more sophisticated and contextually appropriate outputs than would be possible with just text-based information storage.
From GitHub data to a knowledge graph
The next demonstration showcased an even more sophisticated capability: federated data integration where an agent pulls information from one system and automatically creates a structured knowledge graph in another.
Connecting Multiple Systems: Will demonstrated this using Hypermode Agents, which he connected to both GitHub (for accessing repository data) and Neo4j (for storing the resulting knowledge graph). The setup showed how MCP enables agents to work across multiple authenticated services seamlessly.
Querying GitHub: Will started by asking his agent to "show me a list of my 10 most popular GitHub repositories." The agent automatically used the GitHub MCP tools to fetch his repository data, authenticating on his behalf and returning information about repositories, including some private ones that were part of his current projects.
Designing the Data Model: Before creating the graph, Will asked the agent to "show me the Cypher queries and data model you would use to create this graph." This demonstrated an important best practice—having the agent explain its approach before taking action. The agent proposed a model that would capture repositories as nodes with properties like name, language, and description, connected by relationships that showed ownership and collaboration patterns.
Automated Graph Creation: Once Will confirmed the approach, the agent began executing write operations against the Neo4j database. Using the Neo4j Cypher MCP server, it automatically generated and executed the database queries needed to create nodes for each repository and establish relationships between them. The agent handled all the complexity of transforming GitHub's API response into a graph structure.
What made this demonstration remarkable was the seamless integration. Will didn't need to write any code, configure APIs, or understand database schemas. He simply described what he wanted in natural language, and the agent handled authentication, data extraction, transformation, and storage across multiple systems.
Real-world applications: From personal knowledge to enterprise intelligence
The combination of persistent memory, natural language database queries, and client-side federation opens up a wide range of practical applications:
Personal Knowledge Management: Many people use tools like Obsidian, Roam Research, or Notion to build personal knowledge bases, manually creating links between related concepts and maintaining complex webs of information. With MCP-powered graph agents, this process could become largely automated. Every conversation you have with an AI assistant could contribute to your personal knowledge graph, automatically identifying key concepts, relationships, and insights that build up over time into a comprehensive map of your interests and expertise.
Team Collaboration: For teams and organizations, the collaborative aspect becomes even more valuable. Imagine a product development team where every conversation with AI assistants contributes to a shared understanding of the product, its users, market conditions, and technical requirements. Instead of knowledge being siloed in individual conversations or documents, it becomes part of a living, growing knowledge graph that any team member can query and contribute to.
Content Generation: During the demonstration, the agent automatically generated a LinkedIn post about the livestream event, complete with appropriate formatting, emojis, and hashtags. The agent pulled this information from the knowledge graph, understanding not just the facts about the event, but the relationships between the people involved, their companies, and the technologies being discussed. This enabled it to create content that was not only factually accurate but contextually rich and appropriately targeted.
Enterprise Data Discovery: The potential for data discovery is perhaps most exciting for larger organizations. Complex enterprises often struggle with data silos, where valuable information exists but is difficult to find or connect across different systems. Graph-powered agents could serve as intelligent explorers, capable of following relationships across multiple databases, APIs, and documents to surface insights that would be nearly impossible to find through traditional search methods.
Navigating the challenges: Security, quality, and scale
While the potential of MCP-powered graph agents is impressive, Michael Hunger emphasized several important considerations for anyone looking to implement these systems in production environments. As he put it, "there's still a number of things that need to be addressed from the MCP community."
-
Security and Trust: "You want to be able to have a trusted MCP server that comes either from a vendor or that you basically have to source code for and that you can verify and validate for what it's doing," Michael explained. Because MCP servers have the ability to read and write data across multiple systems, a malicious or compromised server could potentially exfiltrate sensitive information or perform unauthorized actions.
-
Tool Quality: The ease of creating MCP servers means that anyone can wrap an existing API and publish it as an MCP server, but not all of these tools are well-designed for agent use cases. As Michael noted, "I would probably look at using tools from trusted authors and vendors if you want to do this, because otherwise you can still end up with low quality tools."
-
Access Control: Organizations need to think carefully about what data should be accessible to which agents, and how to maintain appropriate permissions across different systems. This becomes particularly important when using shared knowledge graphs where information from multiple team members might be combined.
-
Scalability: Current MCP implementations favor stateful connections, which Michael identified as one of his "personal pet peeves." As he explained, "stateful servers don't scale as well, right? So if you think about like hundreds of thousands or millions of users for your hosted MCP server, stateful is probably not what you want."
The MCP ecosystem is rapidly maturing, driven in part by participation from major technology companies including Google, Microsoft, AWS, and OpenAI. These organizations are working together to address the enterprise-grade concerns that will be necessary for widespread adoption:
-
MCP Server Registries: Development of trusted repositories of MCP servers with proper versioning, security scanning, and quality assurance—similar to how developers today can easily discover and install packages from npm or pip
-
Enhanced Authentication: Movement toward hosted MCP servers with proper authentication flows, including OAuth and other enterprise authentication systems, making it easier to securely integrate with corporate systems
-
Protocol Evolution: The protocol itself is evolving to support more sophisticated use cases, including bidirectional communication where MCP servers can initiate requests back to the AI agent, and improved support for streaming data
Getting started: Some helpful tools
If you're ready to experiment with MCP-powered graph agents, the good news is that getting started is more accessible than you might expect. You don't need to set up complex infrastructure or become an expert in graph databases overnight:
-
Neo4j Sandbox: Start with free, temporary Neo4j instances that come pre-loaded with sample datasets or allow you to build your own knowledge graph from scratch. The sandbox environment includes the Neo4j Browser for visual exploration of your graph data
-
Claude Desktop: Provides excellent MCP support out of the box through simple JSON configuration. Claude automatically makes MCP tools available in your conversations—start with the Neo4j memory server to build persistent knowledge graphs from your interactions
-
Hypermode Agents: For building agents with natural language, this platform lets you create domain-specific agents, with built-in MCP support for integrating databases, APIs, and other services without needing to understand the underlying protocol details
-
MCP Inspector: Essential for developers who want to create their own MCP servers. This tool allows you to interact with MCP servers directly, examining their capabilities and testing responses before integrating them into agent workflows
The key is to start small and build up your understanding gradually. Try creating a simple knowledge graph from your conversations, then experiment with querying that data using natural language in Hypermode Agents. As you become more comfortable with the concepts, you can expand to more complex scenarios involving multiple data sources and sophisticated agent workflows.
Ready to build your own knowledge graphs using agents? Sign in to Hypermode to get started, and check out the knowledge graph agent tutorial for a step-by-step guide to building knowledge graph agents.